解析フェイズ~モデルを作る&特徴量の見出し~
タイタニック号のtest.csvデータはどのようなものか、前回はカラムの意味とその例(冒頭3行)を確認した。
今回は、当初データそのものを俯瞰してみる。
まずは、各カラムの定義(型)を見てみよう。
|
train.dtypes
|
これにより、trainの中の各カラムの型の表示が可能となる。
|
整数、浮動小数点、文字列型のようになっている。
次に、欠損値を列ごとに確認してみる。
| train.isnull().sum() |
isnull() は、データフレーム内の各セルが NaN(欠損値)であるかどうかを判定し、欠損値なら True を、それ以外なら False を返します。
sum() は、その True(欠損値)の数を各列ごとに集計します。True は数値的には 1 として扱われるため、sum() を使うことで各列にいくつ欠損値があるのかがわかります。
|
このようになり、Ageで177、Cabinで687、Embarkedで2の欠損値があることが分かりました。
ここから先、色んなアプローチがあります。
数字だけに着目するやり方、欠損値部分に平均値を入れるやり方、性別等の文字列を数値化するやり方、カラム自体を増やして、データの抜け漏れを少なくするやり方等様々です。
えいやーっとやってもよいのですが、Pythonに慣れるためにも、少し色んなアプローチをしてみようと思います。
そのためにも、少し特徴量を押さえておきたいので、視覚的にデータをとらえるためにも、まずはライブラリのインポートを行います。
|
# 解説: seaborn ライブラリを sns という名前でインポートしています。seaborn はデータ可視化用の強力なライブラリで、matplotlib を基にして、より洗練されたグラフを簡単に作成できる機能を提供します。
# seaborn は、ヒートマップ、カテゴリ別の棒グラフ、箱ひげ図、ペアプロットなど、多くの統計的プロットをサポートしており、データを視覚的に確認・分析する際に非常に便利です。
# データフレームを直接使って描画することができ、pandas のデータ構造と密接に連携して使うことができます。
import seaborn as sns
# matplotlib ライブラリの pyplot モジュールを plt という名前でインポートしています。matplotlib は Python での基本的なグラフ作成に使われるライブラリで、さまざまな種類のプロット(折れ線グラフ、棒グラフ、散布図など)を作成できます。
# pyplot は matplotlib のサブモジュールで、MATLAB 風のインターフェースを提供します。これにより、非常に簡単にグラフを描画して表示することができます。
# seaborn は matplotlib 上に構築されているため、両者を組み合わせて使うことが多く、matplotlib の細かい制御が必要な場合に便利です。
import matplotlib.pyplot as plt
|
各種グラフによる特徴量の傾向把握
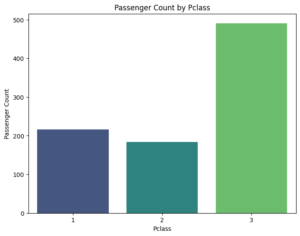
乗客の社会経済的地位を示すクラス(Pclass)を横軸、人数を縦軸として出力してみます。
|
# Pclassごとの乗客数を取得
pclass_counts = train[‘Pclass’].value_counts()
# 棒グラフの作成
plt.figure(figsize=(8, 6))
sns.barplot(x=pclass_counts.index, y=pclass_counts.values, palette=”viridis”)
plt.title(‘Passenger Count by Pclass’)
#軸のタイトルを命名
plt.xlabel(‘Pclass’)
plt.ylabel(‘Passenger Count’)
#棒グラフ出力
plt.show()
|
これを実行すると次のようなグラフとなります。富裕層が比較的多かったものの、世界最大の客船であり、不沈船とも呼ばれた船で、新世界であるアメリカ大陸での成功を夢見たさほど裕福でない人達も多く乗船していた・・・・のかもしれない。
年齢をヒストグラムにして表示してみます。
|
# Ageのヒストグラムを作成
# サイズを指定
plt.figure(figsize=(8, 6))
sns.histplot(train[‘Age’].dropna(), bins=30, kde=False, color=’skyblue’)
plt.title(‘Histogram of Age’)
plt.xlabel(‘Age’)
plt.ylabel(‘Frequency’)
plt.show()
|
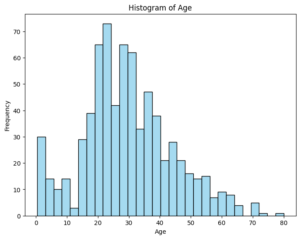
891人のデータ中177欠損値なので、19.87%がカウントできない状況であり、評価はなんとも難しいのですが、20~30代と若い人達が多いと思われます。
男女性別を円グラフにて表示します。
|
# Sexごとのデータを集計
sex_counts = train[‘Sex’].value_counts()
# 円グラフの作成
plt.figure(figsize=(4, 4))
plt.pie(sex_counts, labels=sex_counts.index, autopct=’%1.1f%%’, startangle=90, colors=[‘skyblue’, ‘lightcoral’])
#タイトルの命名
plt.title(‘Passenger Distribution by Sex’)
plt.show()
|
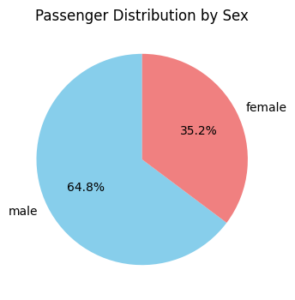
男性の方が三分の二を占めています。仕事でアメリカに行く、という人も多かったのでしょう。
2つの要素の相関を視覚化するための散布図についても描いてみます。
ここでは年齢と運賃の相関を散布図表現してみました。
|
# AgeとFareの散布図を作成
plt.figure(figsize=(8, 6))
sns.scatterplot(x=’Age’, y=’Fare’, data=train, color=’coral’, alpha=0.5)
plt.title(‘Scatter plot of Age vs Fare’)
plt.xlabel(‘Age’)
plt.ylabel(‘Fare’)
plt.show()
|
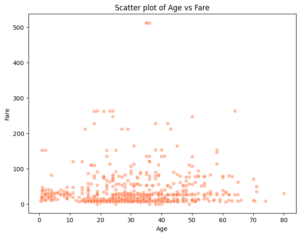
今回、「若い人ほど安いチケットを買って、年配の人ほど高いチケットが買える」という正の相関を予測して、カラム選択を行いましたが、ちょっと予測が外れてしまいました。
wikiによると、乗客の細かな背景が様々記載されているのですが、、、、ここはデータサイエンティストの場。データから読み取ることが主眼なので、その手の謎解きはまた別の機会に。
最後は散布図行列です。
すべてのカラム同士の相関を、散布図で表現するものです。これを使えば、見落としはないかも笑
|
# 散布図行列を作成
sns.pairplot(train)
plt.show()
|
